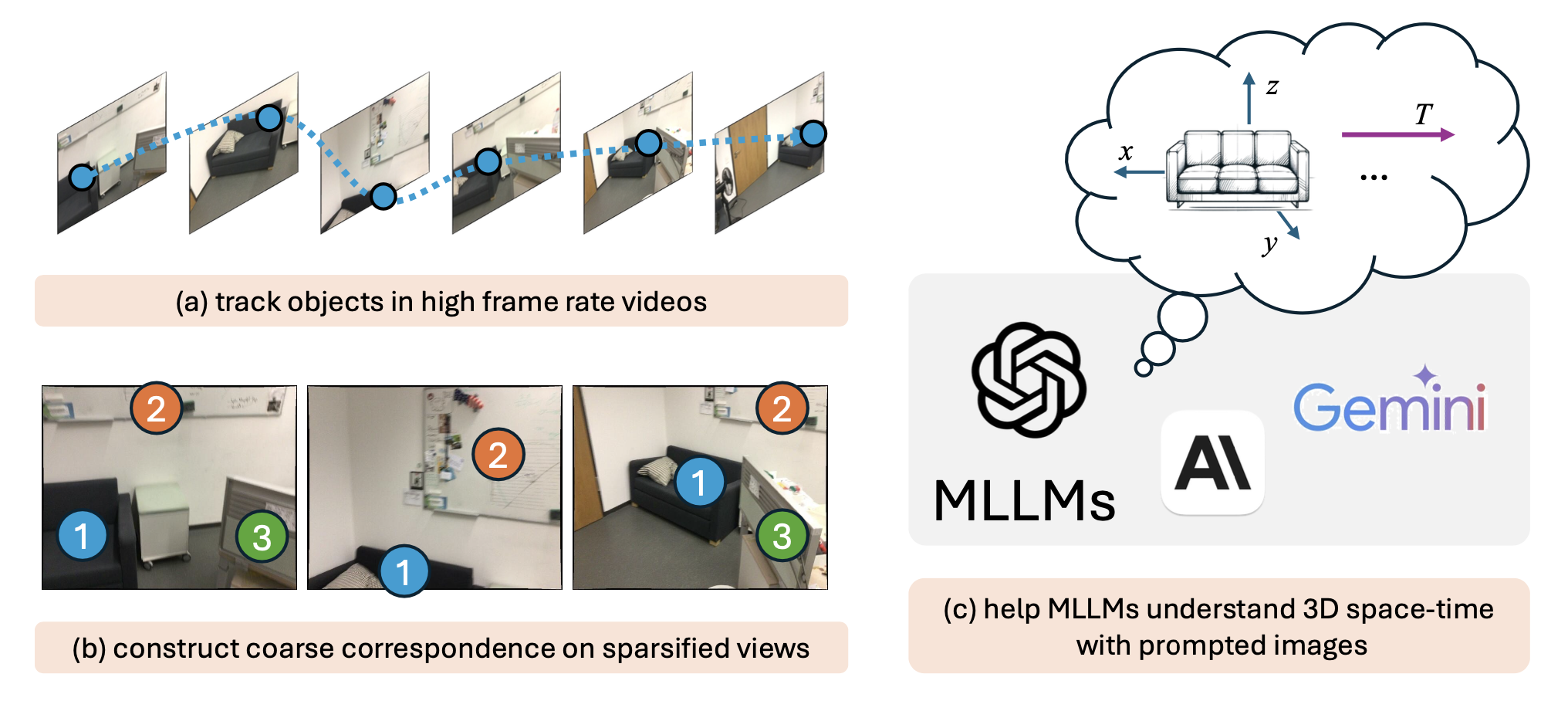
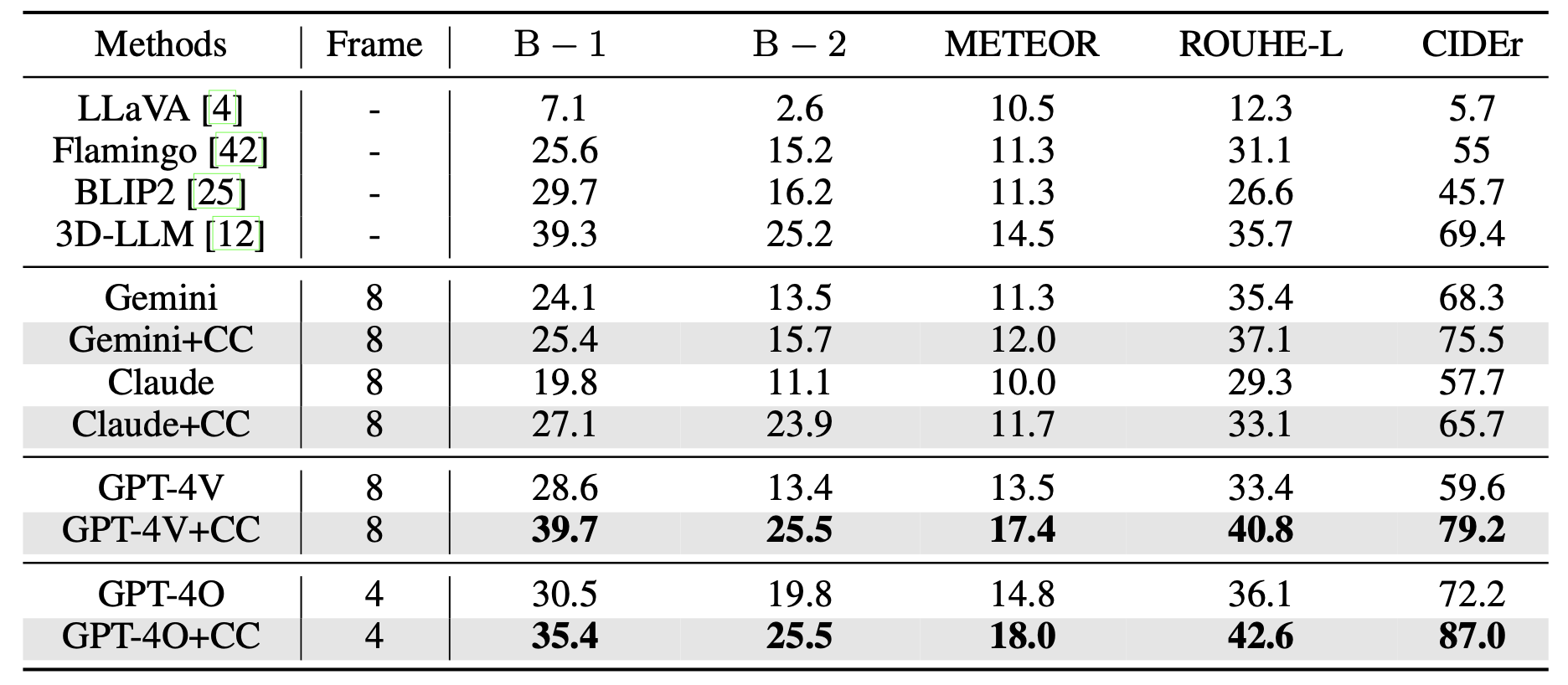
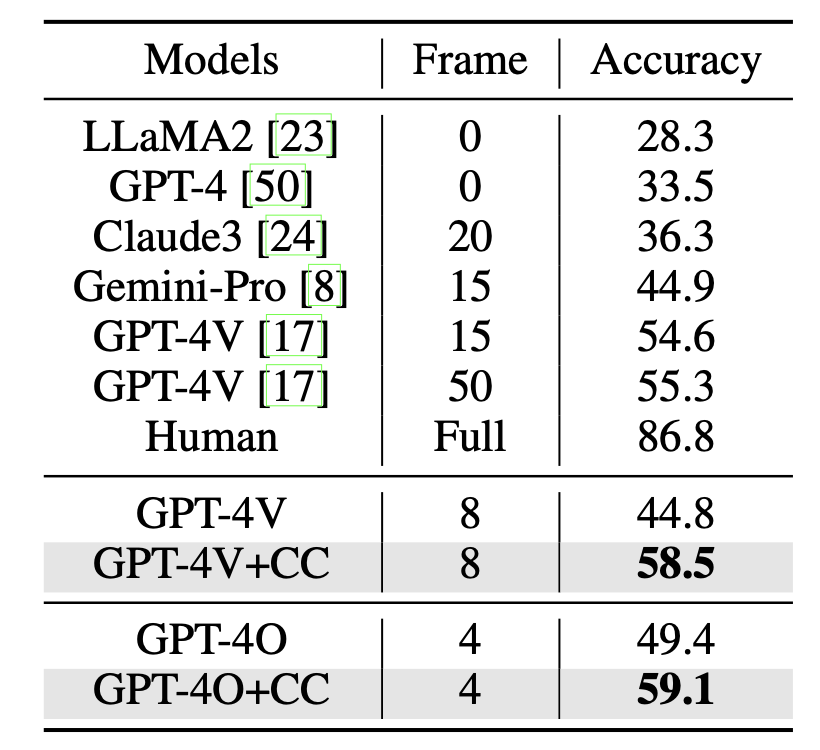
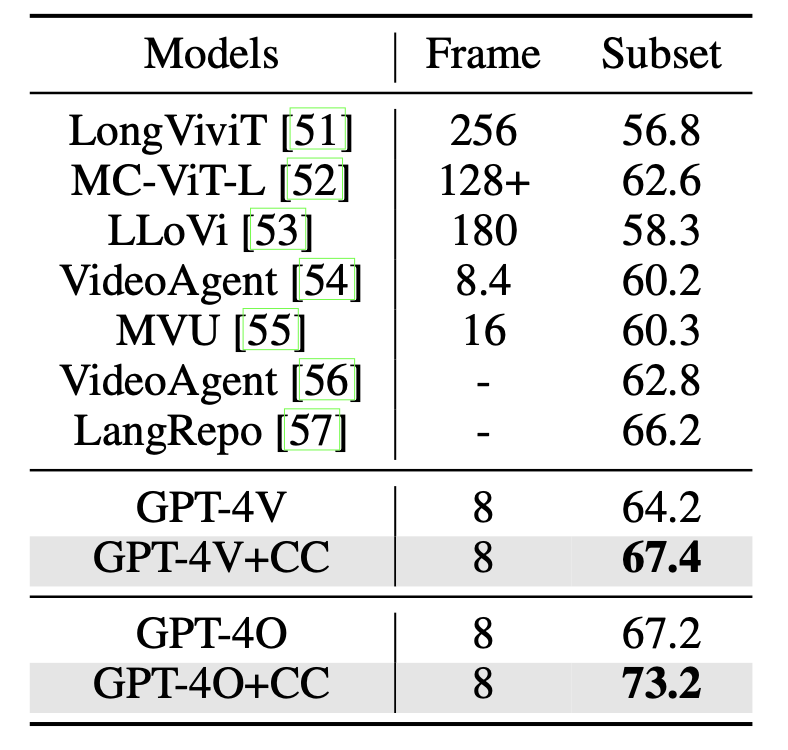
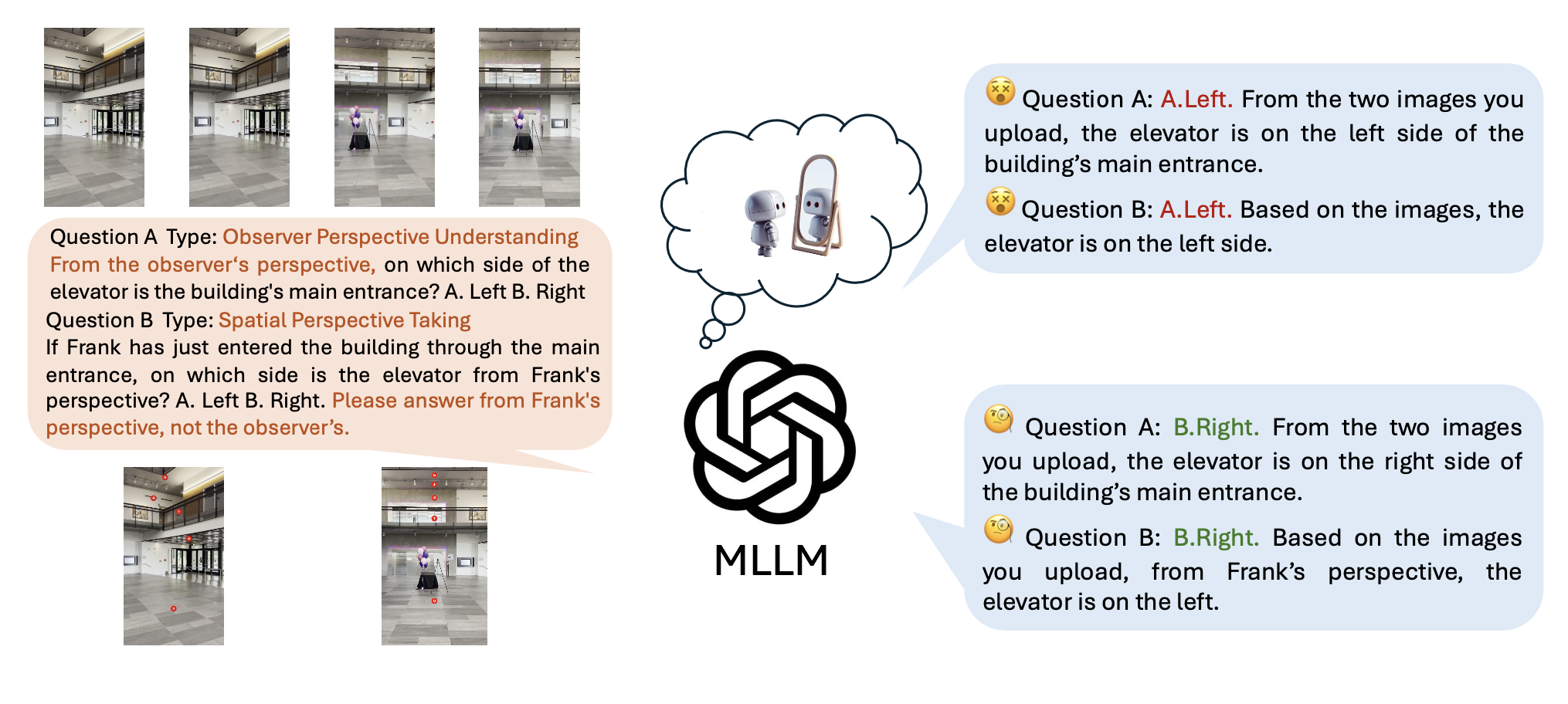
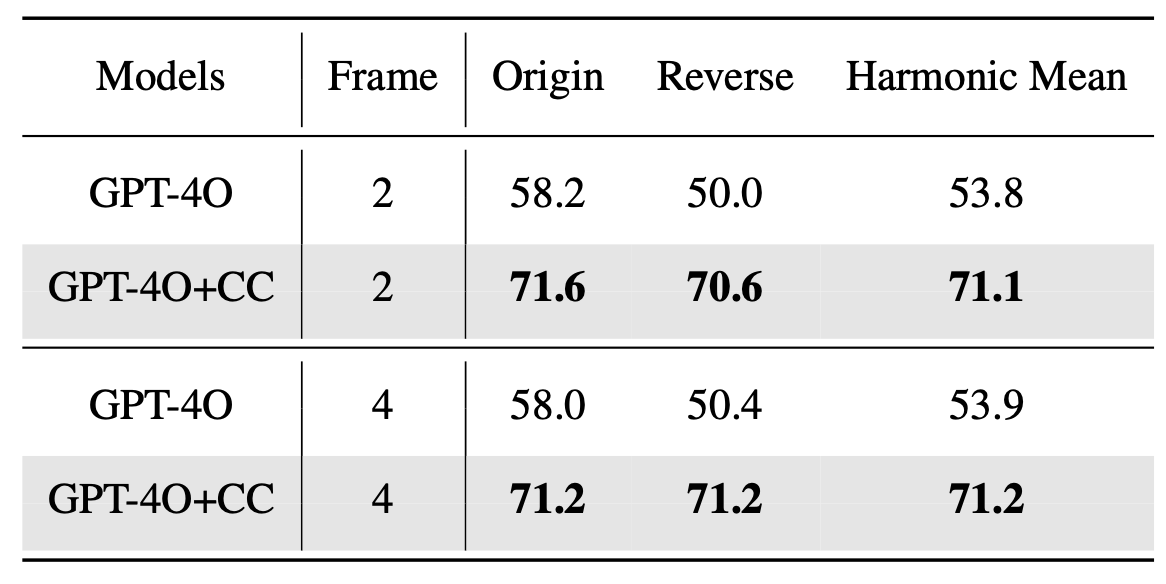
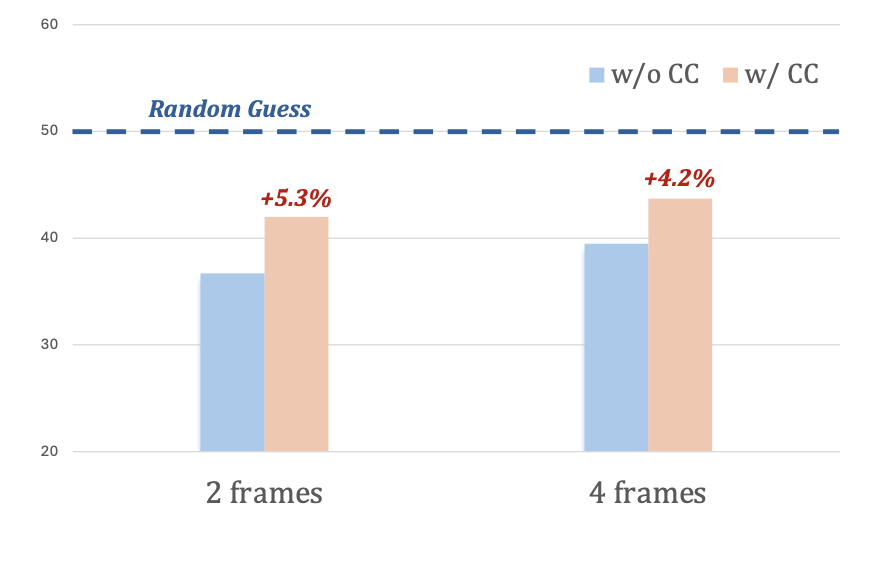
Coarse Correspondences
Coarse Correspondences is a simple, training-free, effective, and general-purpose visual prompting method to elicit 3D and temporal understanding in multimodal LLMs. Our method uses a lightweight tracking model to find object correspondences between frames in a video or between sets of image viewpoints.